適合率(precision)と再現率(recall)
情報検索の有効性の程度を示す評価指標として、適合率(precision、精度とも呼ばれている)と再現率(recall)がある。
データベースには、様々なデータが格納されているが、適合条件が与えられたとき、概念的に、その適合条件を満たすデータと満たさないものに分類される(図1の斜線の左右の領域)。
一方、情報検索によって検索されるデータ(R)は、楕円で示した関係にある。集合としては、次の関係が成り立つ。
U = A ⋃ D
A ∩ D = ∅
R = B ⋃ C
B ∩ C = ∅
B = R ∩ A
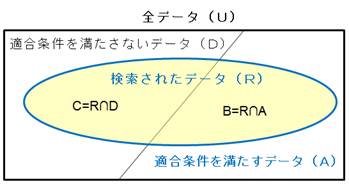
図1.検索条件とデータの分類
適合率(精度)の定義
適合率は、以下の式で定義される指標である。言い換えれば、検索した結果に適合データ(正解となるデータ)がどれだけ含まれているかを示すものである。
適合率= ![]() =
= ![]() =
= ![]()
再現率の定義
再現率は、以下の式で定義される指標である。言い換えれば、適合データ(正解となるデータ)全体のどれだけが検索結果に含まれているかを示すものである。
再現率= ![]() =
= ![]()
F値(F-measure)の定義
適合率と再現率の調和平均をF値と呼んでいる。
F値= ![]() =
=
![]()
一般に、F値が高ければ、性能が良いことを意味する。定義より0≦適合率≦1と0≦再現率≦1であることから、0≦F値≦1となる。
考察
検索したいデータが複雑な構造(側面)を持ったデータであるとき、ユーザが意図した“適合データ”をコンピュータが処理可能な“検索条件”で検索できない場合が発生する。情報検索の適合率、再現率という指標は、このような状況下で有効な指標である。一般に、検索条件を厳しくすれば、適合率は上がるが、再現率は下がる傾向にある。逆に、検索条件を緩めれば、再現率は上がるが、適合率は下がる傾向にある。
一方、ユーザが意図した“適合データ”であるかの判断が難しいものもある。例えば、インターネット上の文書(論文)を一定のキーワードで検索したとする。検索結果として得られた文書(論文)は、ある人にとっては関連性があると判断するが、別の人にとっては関連性が無いと判断することも起こり得る。問題領域によっては、“適合データ”を定義することも難しい場合も起こり得る。
――Copyright(C) 2014 Tokyo Polytechnic University (東京工芸大学) All rights reserved――