Aprioriアルゴリズム
データマイニング(Data Mining)とは、膨大なデータの集積から何らかの知識(傾向、法則、一般的ルール)を導出する方法を探る研究分野である。現在、データマイニングは、コンピュータ技術の活発な研究分野になっている。その発端となったのが、1993年に Agrawalらが提起した頻出する集合を列挙すること(頻出集合列挙問題)と、それに対する効率のよい Apriori アルゴリズムに関する研究である[1][2]。
これらの研究は、スーパーマーケットでの買い物かごの内容を調べて、販売促進や店舗レイアウトに役立てようというバスケット分析を指向したものであるが、その枠組みが一般的なデータ解析に適用できる柔軟なものであることが評価され、今後もデータマイニング主要技術の一つとして位置づけられていくと考えられる。
Aprioriアルゴリズムの主な機能は、頻出アイテム集合の検出と相関ルールの検出である。以下、機能の概要を見てゆく。
A: Aprioriアルゴリズム(頻出アイテム集合の検出)
頻出アイテム集合は、処理対象とするデータ集合に一定数(閾値minsupとして与えられる)以上含まれている要素の集合と定義される。頻出アイテム集合を検出することは、データマイニングの基本的な問題であり、相関ルールの検出をはじめとするさまざまな応用の前提となる。
頻出アイテム集合の検出アルゴリズムを図示すると、以下のようになる。処理としては、最初に1個の要素からなる候補集合を生成し(C1)、発生個数が閾値以上であるという条件で「ふるい分け」し、頻出アイテム集合を作り出す(L1)。次に、頻出アイテム集合(L1)の要素を組み合わせ2個要素からなる候補集合を生成し(C2)、発生個数が閾値以上であるという条件で「ふるい分け」し、頻出アイテム集合を作り出す(L2)。この処理を繰り返すというものである。

頻出アイテム集合の検出アルゴリズムを文章で書いたものを、以下に示す。
1. データ集合を構成する1個の要素で、かつ、閾値minsup以上の発生率を満たす要素の集合をL1とする。
2. 長さk−1の集合Lk-1の要素から長さkの全組合せCkを作成する。
3. c ∈Ckのうち、その部分集合がLk-1に含まれないものをCkから取り除く。
4. c ∈Ckのサポートを計算する。与えられた閾値minsup以上の値の要素を取り出し、長さkの集合Lkを作成する。
5. 2から4の手続きを、Lkが生成できなくなるまで繰り返す。
具体的なデータを使って、頻出アイテム集合検出アルゴリズムを確認してゆく。
Aprioriアルゴリズムが対象とするデータ集合の要素は、要素の集合であり、トランザクションとも呼ばれている。以下に、学生が履修する科目の集合(トランザクション)の例を示す。
T1: {データーベース、 画像処理、 Javaプログラミング}
T2: {画像処理、 Cプログラミング}
T3: {Cプログラミング、 Webデザイン}
T4: {Cプログラミング、 画像処理、 Javaプログラミング}
T5: {画像処理、 Javaプログラミング、 ネットワーク、 Cプログラミング、 データーベース}
T6: {ネットワーク、 Javaプログラミング、 データーベース}
T7: {Javaプログラミング、 データーベース}
これらの履修科目の集合(トランザクションの集合)は、以下のような表として表現することもできる。
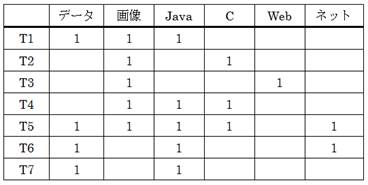
ここで、閾値minsup= 0.5 あるいは50%と仮定する。トランザクション数は7であり、minsup= 0.5であることから、トランザクションの集合に3.5回(すなわち4回)以上発生する要素(の組み合わせ)を求めることになる。
上記の表で、4回以上発生している頻出アイテム集合L1は、以下の通りである。なお、カッコ内の数字は発生個数を示している。
{データーベース}(4)
{画像処理}(4)
{Javaプログラミング}(5)
{Cプログラミング}(4)
次に、L1からC2を生成すると以下のようになる。
{データーベース、画像処理}(2)
{データーベース、Javaプログラミング}(4)
{データーベース、Cプログラミング}(1)
{画像処理、Javaプログラミング}(3)
{画像処理、Cプログラミング}(3)
{ Javaプログラミング、Cプログラミング}(2)
上記の表で、4回以上発生している頻出アイテム集合L2は、以下の通りである。
{データーベース、 Javaプログラミング} (4)
抽出された要素数は2個であり、3個要素からなる候補集合(C3)の生成ができないので、頻出アイテム集合の検出アルゴリズムは終了する。以上の結果をまとめると、検出された頻出アイテム集合は、以下の通りである。
{データーベース}(4)
{画像処理}(4)
{Javaプログラミング}(5)
{Cプログラミング}(4)
{データーベース、 Javaプログラミング} (4)
B: Aprioriアルゴリズム(相関ルールの検出)
頻出アイテム集合から相関ルールを検出する方法の一つに、確信度(confidence、信頼度とも呼ばれる)を使う方法がある。求めようとする相関ルールをX ⇒ Yと記述することとする。ここで、X、Yともに、トランザクションTの要素である。すなわち、X∪Y∈Tである。相関ルールをX ⇒ Yの確信度は、以下の式で定義される。ここで、σ(X)は、要素Xを含むトランザクション数を示す。
確信度(X、 Y)= ![]() =
= ![]()
アイテム集合からルールを求め、確信度が一定数(閾値minconf)以上の場合は、興味深い相関ルールとして出力する。相関ルールは2項目以上で構成される頻出アイテム集合が対象になる。上記の履修科目の集合の場合、該当する頻出アイテム集合は、{データーベース、 Javaプログラミング}であることから、確信度は以下のように計算される。
確信度(データーベース、 Javaプログラミング)= ![]() = 100%
= 100%
確信度(Javaプログラミング、
データーベース)= ![]() = 80%
= 80%
従って、以下の相関ルールが検出される。
データーベース ⇒ Javaプログラミング (確信度100%)
Javaプログラミング ⇒ データーベース (確信度80%)
確信度の閾値minconf=0.9 の場合、興味深い相関ルールは、「データーベース ⇒ Javaプログラミング」となる。
[1] R.Agrawal, T.Imielinski, and A.Swami: Mining
association rules between sets of items in large databases, In Proceedings of
the 1993 ACM SIGMOD International Conference on Management of Data, pp.207-216,
1993.
[2] R.Agrawal and R.Srikant: Fast algorithms for
mining association rules, In Proceedings of 20th Int. Conf. Very Large Data
Bases, VLDB, pp.487-499, 1994.
――Copyright(C) 2014 Tokyo Polytechnic University (東京工芸大学) All rights reserved――